

Dr. Chris Hanretty analyses the current bookmakers predictions for the general election 2015. The odds from Ladbrokes imply Labour will fall short of a majority, he argues.
At the time of writing, bookmakers Ladbrokes offer odds on the winning parties in 449 of the 632 mainland Britain constituencies. Betting odds offer useful information about the probability of events happening. A bookmaker that offers a return of 100-to-one on an event that has a one-in-ten chance of happening rather than a one-in-a-hundred chance of happening is unlikely to stay in business long.
In markets with multiple outcomes, fractional odds can be converted to implied probabilities quite easily. Specifically, we can turn fractional odds into decimal odds — so that odds of 11/4 become 3.75 (1 + 11/4) — and turn these decimal odds into implied probabilities by dividing one by the odds, so that 3.75 become 26.67% (1 / 3.75). Because bookmakers quote odds to make a profit, the sum of implied probabilities will probably exceed 100% — and so we have to divide these implied probabilities by their sum.
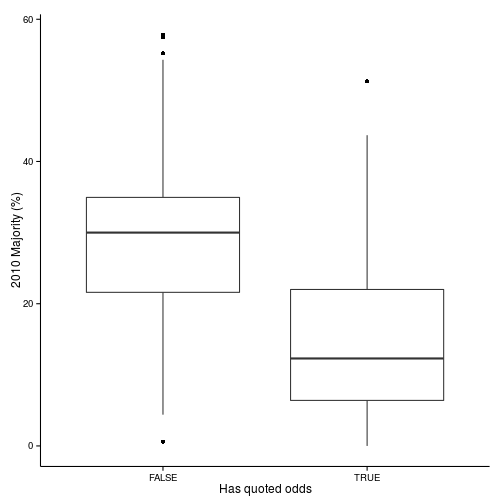
The constituencies for which we have odds for are not a random sample of constituencies. Rather, they’re constituencies which are more `interesting’ — in the sense of having smaller majorities. We can see that in the following box-plot, which plots the 2010 majority of constituencies with and without quoted odds.
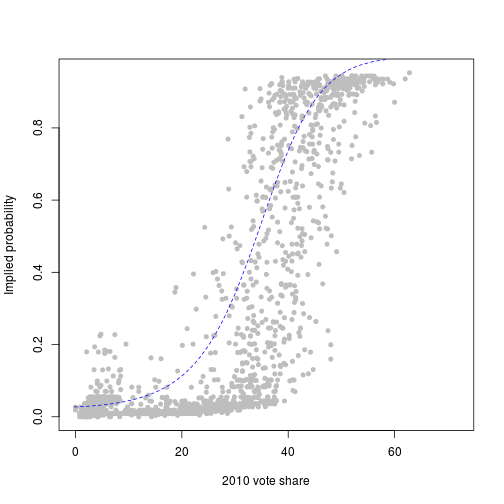
Nevertheless, we can use information from the constituencies for which we do have information to generate implied probabilities for the remaining constituencies. The plot below is a scatter-plot of the 2010 vote share of each party against their implied probability of winning, according to the odds. Overlaid is a curve from a regression model, which shows where the implied probability `ought’ to lie, given what we know about 2010. (Technical note: it’s a beta regression with a polynomial of order three and party dummies; the curve is a fitted curve for Labour. If we feed that regression model the 2010 vote shares for the remaining constituencies, we can get new implied probabilities out.)
What happens when we add these probabilities together to get an overall prediction of the distribution of seats? We see something like the table below.
| Party | Seats |
|---|---|
| Conservatives | 260.21 |
| Labour | 286.80 |
| Liberal Democrats | 42.96 |
| SNP | 12.12 |
| Plaid Cymru | 3.18 |
| Greens | 1.78 |
| UKIP | 22.68 |
| Other | 2.28 |
Thus, when we aggregate constituency betting markets, we get what look like remarkable over-estimates of the number of seats likely to be won by UKIP and the Liberal Democrats. This is likely due to the tendency for bookmakers to offer odds such that
“probabilities implied in the odds are too low for favourites, and too high for longshots, in relation to the frequency of winning outcomes”
In other words, bookmakers repeatedly offer 1-in-100 odds for parties like UKIP without realizing that they’re implying that UKIP should win six-and-a-half seats even if they’re at 1/100 everywhere. What’s strange is that Ladbrokes is also offering odds for Liberal Democrat and UKIP seat tallies that seem inconsistent with these constituency-by-constituency estimates. There’s an arbitrage opportunity for someone here…
We can attempt to correct for this favourite/longshot bias by using information about odds and outcomes in the previous general election. Cunningham, Sudulich and Wall have analysed the effectiveness of betting markets as predictors of seat level outcomes in the 2010 general election. Although they use Betfair data rather than odds from a bookmakers (as we do here), very often the odds from betting exchanges and bookmakers are very similar (partly to prevent obvious arbitrage opportunities emerging). By taking their data on final implied probabilities, and running another regression model which tries to transform the implied probabilities to best match who actually won the seat (technical translation: by running logistic regression using the logit transformed implied probabilities as a predictor), we can “correct” the bookmakers’ implied probabilities using the parameters estimated on 2010 data.
The table below shows the results when we correct probabilities in this way, and aggregate over all seats.
| Party | Seats |
|---|---|
| Conservatives | 272.99 |
| Labour | 310.43 |
| Liberal Democrats | 36.39 |
| SNP | 9.33 |
| Plaid Cymru | 2.78 |
| Greens | 0.77 |
| UKIP | 5.75 |
| Other | 0.77 |
The negative effect on the forecast seat shares for UKIP is dramatic — almost as dramatic as the positive effects on the forecast seat shares for the two largest parties. UKIP’s forecast seat share is still north of what is implied by the separate markets on UKIP seats, which implies that Ladbrokes’ odds aren’t entirely consistent even after correction — but the shape of this forecast is very different to that implied by the previous table.
Dr. Chris Hanretty is a Lecturer in Politics at the University of East Anglia.




Very interesting. Speaking as Ladbrokes Head of Politics, I think you have done a good job of teasing out the problems with just aggregating the implied probabilities. We do something very similar here to try to produce a “correct” forecast which should tally up with all of our other prices (total seats, majority betting). It doesn’t quite – partly because we are very cautious with our UKIP odds.
@Matthew: thanks for the comment. I think it’s probably important for me to realize that you face a different loss function. I can get my head around calibrating probabilities to maximize the percentage correctly predicted; I wouldn’t know how to do that whilst still pulling the punters in and minimizing worst-case losses…
Yes, there are some good reasons why our odds don’t exactly correspond to our expectations, or just reflect the balance of money being bet. There’s a blogpost from before the 2010 election which covers some of this:
http://www1.politicalbetting.com/index.php/archives/2010/02/25/the-ladbrokes-election-forecast/
As it happens, we now have all of the GB seats priced up although, as you correctly pointed out, there probably isn’t much new information contained in the constituencies originally left out of the analysis. I doubt it would make more than a seat or two’s difference to your “corrected” estimate.
Did you manage to find an efficient way of extracting all of the prices from our site, or was it a manual job? We might be able to provide you with the data in an updating feed you could use, if you were interested.